
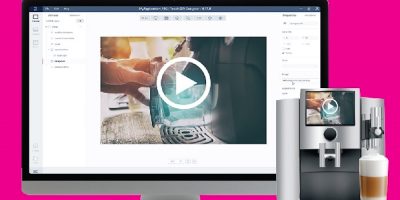
The TouchGFX Version 4.18 from STMicroelectronics is for user-interface development with STM32 microcontrollers, adding video playback, enhanced tools for multi-developer collaboration, and support for new X-NUCLEO display kits.
By allowing playback of Motion-JPEG (MJPEG) video files, TouchGFX aids small devices such as home-automation products, wearables, medical devices and industrial sensors, allowing rich features such as instructional guides or entertaining startup and pause screens to enhance the user interface. Developers can use their own MJPEG files or choose from the sample movies provided. A new video widget in TouchGFX Designer, with properties including start, stop, repeat, and go-to-frame, simplifies prototyping and is added to the application by drag and drop, says ST.
TouchGFX 4.18 allows video decoding in either software or hardware. Hardware decoding is possible with STM32 MCUs that contain a suitable decoding peripheral, such as the STM32F769 and STM32H7B3. Software decoding is available on all series devices except the STM32G0 series. Various strategies for video buffering, including direct rendering to the frame buffer and double buffering, help optimise memory demand and performance.
Additional new features of TouchGFX 4.18 include enhanced support for collaborative working, using XML to store text data and translations. XML simplifies sharing and merging various elements of the project as multiple team members contribute. The features of previous TouchGFX versions are retained, including the partial frame buffer for low RAM use, ultra-efficient rendering that prevents tearing effects, and support for low-cost non-memory-mapped SPI Flash.
For an easy start to GUI development projects, TouchGFX 4.18 comes with examples showing how to use the new video capabilities and the necessary TouchGFX board setup for the STM32 Discovery boards.
ST has also updated and extended the selection of display shields that help developers get their user-interface projects running. The updated X-NUCLEO-GFX01M2 for Nucleo 64 boards has a 2.2” QVGA serial interface display and now supports the NUCLEO-WB55RG, making it easy to add a display to a Bluetooth application. A new X-NUCLEO-GFX02Z1 for Nucleo 144 has a high-speed parallel interface and QSPI Flash memory on-board, supporting among others the NUCLEO-U575ZI-Q Both are supported in TouchGFX 4.18.
Go to https://www.st.com/content/st_com/en/ecosystems/stm32-graphic-user-interface.html




